En https://gestioncolaborativa.buenosaires.gob.ar el Gobierno de la Ciudad de Buenos Aires permite hacer diferentes tipos de trámites, denuncias, reclamos, etc.
En particular, yo lo use para denunciar un auto abandonado en la puerta de mi casa. En el mismo hay que subir una foto, completar unos datos del auto (color, patente, etc) y luego ESPERAR. Al día siguiente de hacer la denuncia ya estaba impaciente, quería tener una idea de cuanto tardaría mi trámite.
La web ofrece, a medida que el tramite se mueve un estado que se va actualizando, con esta pinta:
Lo que no aparece, es la estimación de tiempo, o como es la distribución de espera típica. Lo cual es raro teniendo en cuenta la cantidad de datos pasados que tienen.
Como quería tener una noción de como se resuelven estos tramites, baje los “pedidos” del sistema. Casi todos los del 2017 y los del 2018 hasta el 10 de Mayo o similar (en total fueron unos 1.1 millones).
Para bajarlos, entré a la url que se genera luego de cargar un pedido, por ejemplo si mi trámite es el 1234/18, la web donde se puede ver es:
Que en realidad, lo que hace es pegarle a otro entrypoint para obtener los datos en formato JSON, para el mismo ejemplo el otro entrypoint es:
Esta entrada devuelve los datos en formato JSON con la info que se ve en la pantalla del trámite (y un poco más!)
La data que devuelve, y la cantidad de datos que hay, dan para varios post, pero traté de centrarme en mi inquietud: Encontrar el tipo de tramite que hice yo y medir como eran las dispersiones típicas de resolución y de tiempos.
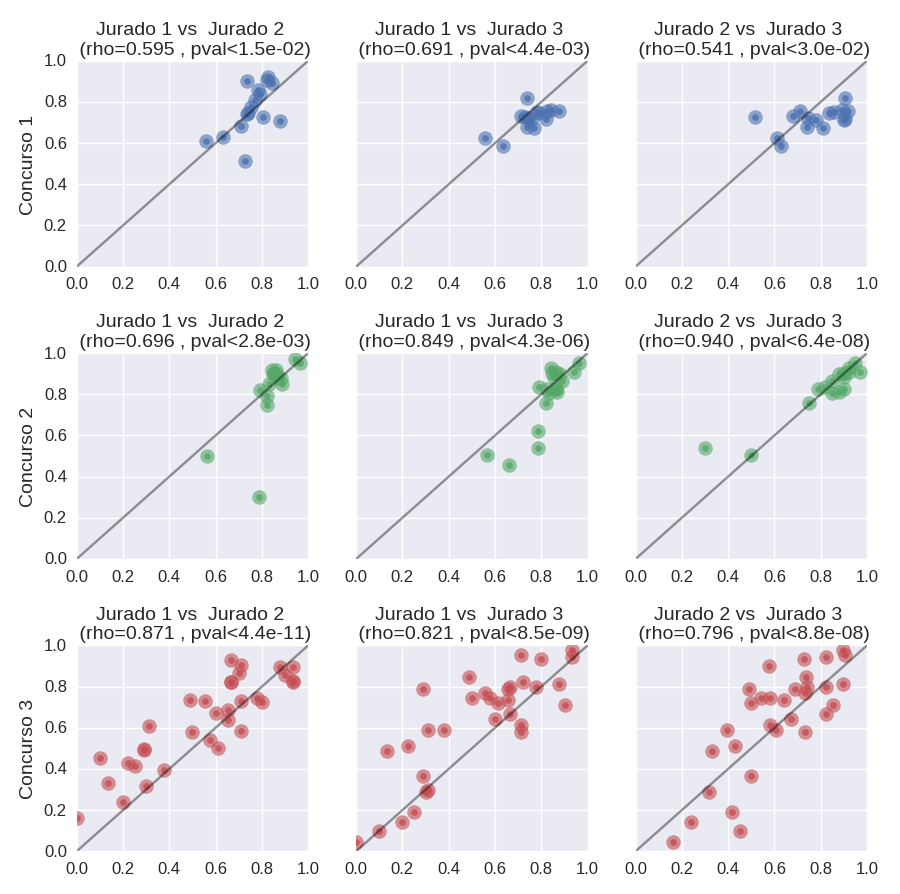
En principio, había un campo importante que era el tipo, en toda la muestra que obtuve, encontré 5 tipos diferentes y se distribuían así.
TIPO
| |
DENUNCIA
|
19%
|
QUEJA
|
2%
|
RECLAMO
|
15%
|
SOLICITUD
|
23%
|
TRAMITE
|
41%
|
Los de tipo TRAMITE, que eran la mayoría, a su vez eran ‘SOLICITUD DE PARTIDAS', y tenían casi todas la misma coordenada y dirección que corresponden al Registro Civil Central (Uruguay Av. 753 ) por lo que supongo que los pedidos tramite aparecen en esta web también. En el caso de mi pedido, era de tipo RECLAMO.
Otra información relevante de los datos, es el CONCEPTO, hay varios, la mayoría nuevamente corresponde a SOLICITUD DE PARTIDAS. El que origine yo, se llamaba "Remoción de vehículo / auto abandonado".
De los 7369 pedidos de “Remoción de vehículo”, 73% tenían estado 100%, de las cuales 43% correspondían a “ya resolvimos la solicitud”, otros 43% a ‘nuestro verificador no pudo identificar el problema que originó el pedido’ y lo restante correspondieron también a pedidos con resultado negativo por parte del que emite la solicitud (la solicitud no fue conducente por no poder ser identificada o por no ser competencia del gobierno de la ciudad, la solicitud no contaba con la información suficiente para tratar el pedido y por lo tanto fue desestimada por favor realiza una nueva solicitud aportando la mayor cantidad de datos posible, la solicitud no fue conducente o finalizó sin resultados, etc)
Osea, solo el 32% (0.73 * 0.42) terminan de manera exitosa para el que genera el pedido al gobierno de la ciudad en este tipo de tramites.
A priori pensé que tal vez dependía del barrio el éxito del tramite y el tiempo de resolución, pero a ojímetro estas dos variables parecían ser invariantes en toda la ciudad. Por ejemplo, así se distribuían en la ciudad las denuncia de auto abandonado en función a todas las denuncias (en azul)

En fin, suponiendo entonces que el barrio no modificaba lo que tarda un pedido en ser resuelto, miré las distribuciones de tiempos para tramites de “Remoción de vehículo”, separando en los que terminan favorablemente para él que hizo el pedido y los que no.

Las distribuciones están muy buenas, se separan bastante y esencialmente con sentido. Si te rebotan, te robotan rápido, si pasas masomenos los 10 días es mas probable que salga bien y remuevan el auto (puesto que a su vez, la cola de la distribución de abajo tiene mucha menor cantidad de casos que la de arriba)
En fin, luego de ver esto, tengo mas esperanza de que me den bola. Estaría bueno que muestren esta info en cada pedido…
... aunque ya voy 50 días y el auto sigue ahi :p